 网硕互联帮助中心
网硕互联帮助中心文章目录
- 一、Reactor是什么?
-
- Reactor基本原理
- Reacto针对业务的优点
- 二、服务器百万并发(基于Reactor)
-
- 源码
- 核心思想
- 工作流程
-
- 执行指令
- BUG整理
- 三、思考问题
-
- 1. 相比直接调用epoll,reactor的优势体现在哪?
-
- (1)epoll的局限
- (2)reactor的优势
-
- 1. 缓冲区管理
- 2. 回调机制的灵活性
- 3. 状态管理与处理
- 4. 易于扩展
- 2. Reactor模式如何实现 网络与业务的隔离?
-
- (1)网络层和业务层的定义
- (2)Reactor模式如何实现隔离
- 一句话概括Reactor
- 解耦的理解
一、Reactor是什么?
Reactor基本原理
register(注册对应的事件,比如read、write、send…)
callback(根据不同事件调用不同回调函数)
Reacto针对业务的优点
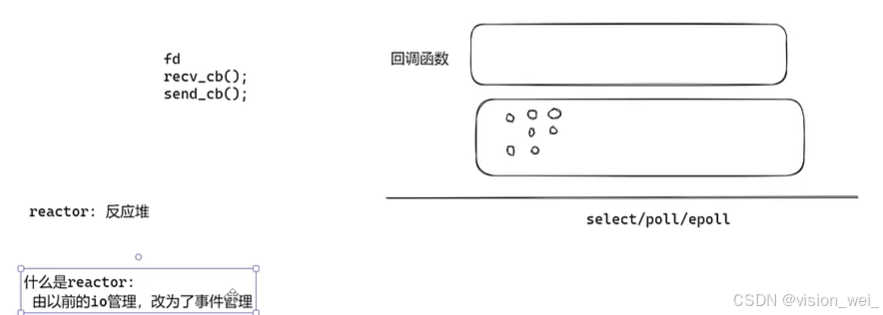
二、服务器百万并发(基于Reactor)
源码
reactor.c
#include <errno.h>
#include <stdio.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <string.h>
#include <pthread.h>
#include <unistd.h>
#include <poll.h>
#include <sys/epoll.h>
#include <errno.h>
#include <sys/time.h>
#include "server.h"
#define CONNECTION_SIZE1048576 // 1024 * 1024
#define MAX_PORTS20
#define TIME_SUB_MS(tv1, tv2) ((tv1.tv_sec – tv2.tv_sec) * 1000 + (tv1.tv_usec – tv2.tv_usec) / 1000)
// BUFFER_LENGTH: 用于存储读取和写入数据的缓冲区大小
// CONNECTION_SIZE: 最大连接数
// MAX_PORTS: 最大监听的端口数
// TIME_SUB_MS 宏用于计算两个 struct timeval 类型的时间差(单位为毫秒)
int accept_cb(int fd);
int recv_cb(int fd);
int send_cb(int fd);
int epfd = 0; //epoll 实例的文件描述符
struct timeval begin; //以 fd 为下标的连接数组,用于快速查找连接信息
struct conn conn_list[CONNECTION_SIZE] = {0}; //conn结构体 用来描述每个fd连接的状态
/*
功能:向 epoll 实例中添加或修改事件
//根据 flag 的值,决定是添加事件(EPOLL_CTL_ADD)还是修改事件(EPOLL_CTL_MOD)
//通过 epoll_ctl 系统调用与 epoll 文件描述符 epfd 交互来管理事件
*/
int set_event(int fd, int event, int flag) {
//是否为添加事件(非零为添加,零为修改)
if (flag) { // non-zero add
struct epoll_event ev;
ev.events = event;
ev.data.fd = fd;
epoll_ctl(epfd, EPOLL_CTL_ADD, fd, &ev);
} else { // zero mod
struct epoll_event ev;
ev.events = event;
ev.data.fd = fd;
epoll_ctl(epfd, EPOLL_CTL_MOD, fd, &ev);
}
}
/*
功能:注册一个新连接,初始化连接信息并添加到 epoll 监听
// event_register 函数用于为一个连接(fd)注册事件并初始化连接的状态(就是注册clientfd)。
// 它设置接收回调函数、发送回调函数,以及连接的读取和写入缓冲区
*/
int event_register(int fd, int event) {
if (fd < 0) return –1;
conn_list[fd].fd = fd;
conn_list[fd].r_action.recv_callback = recv_cb;
conn_list[fd].send_callback = send_cb;
//memset建立buffer缓冲区空间,用于数据通信
memset(conn_list[fd].rbuffer, 0, BUFFER_LENGTH);
conn_list[fd].rlength = 0;
memset(conn_list[fd].wbuffer, 0, BUFFER_LENGTH);
conn_list[fd].wlength = 0;
set_event(fd, event, 1);
}
/*
功能:接受新连接,并注册到 epoll 监听。
// 触发条件:监听 socket 上有新连接(EPOLLIN 事件)
// listenfd(sockfd) –> EPOLLIN –> accept_cb
调用 accept 函数接受连接,返回客户端的套接字 clientfd
注册 clientfd 的事件(监听 EPOLLIN)
打印每次接受连接所花费的时间
*/
int accept_cb(int fd) {
struct sockaddr_in clientaddr;
socklen_t len = sizeof(clientaddr);
int clientfd = accept(fd, (struct sockaddr*)&clientaddr, &len);
//printf("accept finshed: %d\\n", clientfd);
if (clientfd < 0) {
printf("accept errno: %d –> %s\\n", errno, strerror(errno));
return –1;
}
event_register(clientfd, EPOLLIN); // | EPOLLET
//计算client连接耗时
if ((clientfd % 1000) == 0) {
struct timeval current; //内核自带time API
gettimeofday(¤t, NULL);
int time_used = TIME_SUB_MS(current, begin);
memcpy(&begin, ¤t, sizeof(struct timeval));
printf("accept finshed: %d, time_used: %d\\n", clientfd, time_used);
}
return 0;
}
/*
功能:接收客户端数据,并准备回显
// 触发条件:客户端 socket 上有数据可读(EPOLLIN 事件)
读取数据到 rbuffer,如果读取失败或客户端断开连接,则关闭连接
将接收到的数据复制到 wbuffer,准备发送
设置 EPOLLOUT 事件,以便在下一个事件循环中处理数据发送(关注写事件)
*/
int recv_cb(int fd) {
memset(conn_list[fd].rbuffer, 0, BUFFER_LENGTH );
int count = recv(fd, conn_list[fd].rbuffer, BUFFER_LENGTH, 0);
if (count == 0) { // disconnect 客户端断开连接
printf("client disconnect: %d\\n", fd);
close(fd);
epoll_ctl(epfd, EPOLL_CTL_DEL, fd, NULL); // unfinished
return 0;
} else if (count < 0) { // 接受错误
printf("count: %d, errno: %d, %s\\n", count, errno, strerror(errno));
close(fd);
epoll_ctl(epfd, EPOLL_CTL_DEL, fd, NULL);
return 0;
}
conn_list[fd].rlength = count;
//printf("RECV: %s\\n", conn_list[fd].rbuffer);
#if 0 // echo回显数据
conn_list[fd].wlength = conn_list[fd].rlength;
memcpy(conn_list[fd].wbuffer, conn_list[fd].rbuffer, conn_list[fd].wlength);
printf("[%d]RECV: %s\\n", conn_list[fd].rlength, conn_list[fd].rbuffer);
#elif 1
http_request(&conn_list[fd]);
#else
ws_request(&conn_list[fd]);
#endif
set_event(fd, EPOLLOUT, 0); //修改为监听写事件
return count;
}
// 功能:发送数据给客户端
// 触发条件:客户端 socket 可写(EPOLLOUT 事件)
int send_cb(int fd) {
#if 1
http_response(&conn_list[fd]);
#else
ws_response(&conn_list[fd]);
#endif
int count = 0;
#if 0
if (conn_list[fd].status == 1) {
//printf("SEND: %s\\n", conn_list[fd].wbuffer);
count = send(fd, conn_list[fd].wbuffer, conn_list[fd].wlength, 0);
set_event(fd, EPOLLOUT, 0);
} else if (conn_list[fd].status == 2) {
set_event(fd, EPOLLOUT, 0);
} else if (conn_list[fd].status == 0) {
if (conn_list[fd].wlength != 0) {
count = send(fd, conn_list[fd].wbuffer, conn_list[fd].wlength, 0);
}
set_event(fd, EPOLLIN, 0);
}
#else
if (conn_list[fd].wlength != 0) {
count = send(fd, conn_list[fd].wbuffer, conn_list[fd].wlength, 0);
}
set_event(fd, EPOLLIN, 0);
#endif
//set_event(fd, EPOLLOUT, 0);
return count;
}
/*
功能:初始化服务器,创建监听 socket
// 1.创建一个 TCP 套接字
// 2.将服务器绑定到指定端口
// 3.开始监听连接
*/
int init_server(unsigned short port) {
int sockfd = socket(AF_INET, SOCK_STREAM, 0);
struct sockaddr_in servaddr;
servaddr.sin_family = AF_INET;
servaddr.sin_addr.s_addr = htonl(INADDR_ANY); // 0.0.0.0
servaddr.sin_port = htons(port); // 0-1023,
if (–1 == bind(sockfd, (struct sockaddr*)&servaddr, sizeof(struct sockaddr))) {
printf("bind failed: %s\\n", strerror(errno));
}
listen(sockfd, 10);
//printf("listen finshed: %d\\n", sockfd); // 3
return sockfd;
}
int main() {
unsigned short port = 2000;
epfd = epoll_create(1);
int i = 0;
for (i = 0;i < MAX_PORTS;i ++) {
//初始化服务端
int sockfd = init_server(port + i);
//集合队列注册server端口信息
conn_list[sockfd].fd = sockfd;
conn_list[sockfd].r_action.recv_callback = accept_cb;
//向epoll实例中操作事件
set_event(sockfd, EPOLLIN, 1);
}
gettimeofday(&begin, NULL); //计算端口连接时长
//事件循环
while (1) { // mainloop
struct epoll_event events[1024] = {0};
int nready = epoll_wait(epfd, events, 1024, –1);
int i = 0;
for (i = 0;i < nready;i ++) {
int connfd = events[i].data.fd;
#if 0
if (events[i].events & EPOLLIN) {
conn_list[connfd].r_action.recv_callback(connfd);
} else if (events[i].events & EPOLLOUT) {
conn_list[connfd].send_callback(connfd);
}
#else
//for循环里选择采用双if而不是if-else
//是因为双if可以做到:一个循环里,io处理两个不同的回调函数(读和写事件对应的回调函数)
if (events[i].events & EPOLLIN) {
conn_list[connfd].r_action.recv_callback(connfd);
}
if (events[i].events & EPOLLOUT) {
conn_list[connfd].send_callback(connfd);
}
#endif
}
}
}
核心思想
- Reactor模式:通过事件驱动的方式管理 I/O 操作,避免阻塞线程
- epoll框架:Linux 提供的高效 I/O 多路复用机制,用于监听文件描述符(fd)上的事件
- callback回调函数:每个 fd 的事件触发时,调用对应的回调函数(如 accept_cb、recv_cb、send_cb)处理
工作流程
事件注册: 将感兴趣的事件(如可读、可写)注册到epoll,并为每个事件绑定对应的回调函数. 在这里使用了一个循环开辟20个端口,因为一个端口建立的连接数量最大是65536-1024,这里设置好fd和回调函数后用set__event接口调用epoll
int i = 0;
for(i = 0 ; i < MAX_PORT ; i++){
int sockfd = init_server(port + i);
conn_list[sockfd].fd = sockfd;
conn_list[sockfd].recv_action.recv_callback = accept_cb;
set_event(sockfd, EPOLLIN, 1);//关注可读事件
}
事件监听:Reactor 调用epoll_wait等待事件发生。这一步是阻塞的,但不会阻塞整个程序,只阻塞等待事件的线程。
//mainloop
while(1){
struct epoll_event events[1024] = {0};
int nready = epoll_wait(epfd, events, 1024, –1);
...
}
事件触发:当某个事件就绪时,epoll_wait返回就绪事件列表
事件分发:Reactor 遍历就绪事件列表,根据事件类型调用对应的回调函数
for循环里选择采用双if而不是if–else ==> 保证recv和send都可以被正确处理
是因为双if可以做到:一个循环里,io处理两个不同的回调函数(读和写事件对应的回调函数)
if (events[i].events & EPOLLIN) {
conn_list[connfd].r_action.recv_callback(connfd);
}
if (events[i].events & EPOLLOUT) {
conn_list[connfd].send_callback(connfd);
}
事件处理: 回调函数处理事件, eg:调用send发送数据; 数据接收调用recv读取数据; 新连接调用 accept接收连接
在Reactor模型中,主线程负责接收新的连接请求,并将它们转发给不同的处理程序处理,而不是在主线程中直接处理这些请求。其中心思想是将所有要处理的IO事件注册到一个中心IO多路复用器上,同时主线程/进程阻塞在多路复用器上
执行指令
client源码: mul_port_client_epoll.c
server源码: reactor.c
//编译
$ gcc –o reactor reactor.c –mcmodel=medium
$ gcc –o mul_port_client_epoll mul_port_client_epoll.c –mcmodel=medium
//运行
$ ./mul_port_client_epoll [ip地址] [端口号2000]
//代码运行流程
1.初始化服务器,创建监听 socket
2.将监听 socket 注册到 epoll,监听 EPOLLIN 事件
3.进入事件循环,调用 epoll_wait 等待事件
4.当有新连接时,触发 accept_cb,接受连接并注册到 epoll。
5.当客户端发送数据时,触发 recv_cb,接收数据并准备回显
6.当客户端可写时,触发 send_cb,发送数据
//main执行操作:
1.创建一个 epoll 实例
2.为多个端口(port 到 port + MAX_PORTS)初始化服务器,并为每个监听套接字注册 EPOLLIN 事件
3.进入一个无限循环,等待和处理事件(通过 epoll_wait)
//思考?
+ 整集用什么数据结构存储
+ 选择什么数据结构做就绪
BUG整理
四、常见问题
三、思考问题
1. 相比直接调用epoll,reactor的优势体现在哪?
(1)epoll的局限
如果一次发送的数据量较大,直接调用epoll效率是比较低的,因为epoll的逻辑不适合大包传输或连续传输。 eg: epoll会遍历每一个当前就绪的io,若一次发送的数据量超过了char buffer[1024]的上限,则需要后续接收数据再进行拼接,使得效率大打折扣。
(2)reactor的优势
1. 缓冲区管理
连续接收和发送 | 数据完整性 每个连接(通过 conn_list 数组进行管理)都有独立的 接收缓冲区和 发送缓冲区,有效避免数据丢失和混乱。因此当多个连接同时传输数据时,可以独立管理每个连接的通信,不互相影响。
2. 回调机制的灵活性
RCALLBACK回调机制使得在接收到连续数据时,程序能够根据需要采取不同的处理方式。
- eg1: 可以通过判断数据的长度len和内容来确定是否需要等待更多的数据,或者是否已经接收到完整的一批数据。这对于处理连续的数据流非常有用,因为数据可能分批到达,程序可以在每次数据到达时决定如何处理.
- eg2: 如果接收到的数据data>buffer大小,程序可以将数据分割并按顺序处理,直到所有数据完全接收完毕
3. 状态管理与处理
通过 conn_list 中的每个连接状态来管理缓冲区的读写位置,这对于 连续数据处理 是非常有帮助的。通过动态更新连接的缓冲区状态(例如 rlength 和 wlength),程序可以跟踪每个连接接收和发送的进度.
4. 易于扩展
reactor模式使用了结构体和回调函数,因此可以轻松扩展支持 更复杂的连续数据传输逻辑。例如:
+ 增加对接收到数据的分片处理机制,以应对大数据的连续传输。
+ 增加对数据流控制和速率限制的支持,避免连续数据流过快导致的内存溢出或性能问题。
+ 增加对大文件传输的支持,通过回调机制在接收和发送时更精细地控制每个数据块的处理。
2. Reactor模式如何实现 网络与业务的隔离?
(1)网络层和业务层的定义
- 网络层:负责处理所有与网络相关的任务,例如监听连接、接收和发送数据等。这些操作通常是 I/O 密集型的,并且可能会有大量的并发请求。
- 业务层:负责处理应用程序的具体业务逻辑,例如处理用户请求、计算、存储和返回数据等。这些操作通常是 CPU 密集型的,并且依赖于特定的业务需求。
(2)Reactor模式如何实现隔离
-
I/O 事件分发: 网络层的 I/O 事件(如连接请求、数据到达等)由 Reactor(事件循环)管理,它会将这些事件分发给特定的 事件处理器。这些处理器只关心如何处理网络事件,例如接收数据、建立连接等。
-
回调机制: 事件处理器通常使用 RCALLBACK回调函数 来通知业务层执行特定的操作。当网络事件处理完成(例如数据被接收到),网络层会调用相应的业务逻辑处理函数(回调),而业务层则负责对这些数据进行处理和响应。通过这种代码解耦方式,网络层和业务层可以完全解耦。
-
网络层只负责监听和处理网络 I/O 操作,业务层只负责处理实际的业务逻辑。两者之间没有直接的依赖关系,这样就实现了 网络和业务的隔离
一句话概括Reactor
Reactor 设计模式能够通过 事件驱动和回调机制实现 网络层和业务层的隔离,即网络层只负责接收、发送数据和管理连接,而业务层则专注于处理业务逻辑。这样设计的优点是 解耦、灵活性 和 清晰的代码结构,使得系统更加容易扩展和维护
解耦的理解
主程序把回调函数像参数一样传入库函数。只要我们改变传进库函数的参数,就可以实现不同的功能, 并且丝毫不需要修改库函数的实现 
优秀笔记: 1. C++实现基于reactor的百万级并发服务器 2. C++实现基于reactor的http&websocket服务器 3. 采用Reactor网络模型实现HTTP服务器 参考学习: https://github.com/0voice




评论前必须登录!
注册