 网硕互联帮助中心
网硕互联帮助中心CANN加速强化学习推理:策略网络与价值网络优化
强化学习(Reinforcement Learning,RL)是一种通过与环境交互学习最优策略的机器学习方法。RL在游...
强化学习(Reinforcement Learning,RL)是一种通过与环境交互学习最优策略的机器学习方法。RL在游...
YOLOv11改进 | YOLOv11引入LGLBlock大核局部-全局-局部模块,提取长距离语义和边缘细节信息 一、引言 在目标检测任务中&...
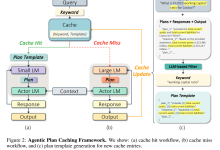
文章总结与翻译 一、主要内容 该研究针对基于大语言模型(LLM)的智能体(Agent)在复杂工作流中因大量规划和推理导致的高成本、高延迟问题,提出了一种名为...
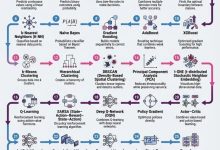
从预测房价的线性回归,到驱动大语言模型的 Transformer,AI 算法的版图广阔且层层递进 —— 很多数据科学家容易陷入 “会...

本文主要讲述了一体化模型进行去噪、去雨、去模糊,也就是说,一个模型就可以完成上述三个任务。实现了良好的图像复原功能! ...
前面已经搭好了:能用 RAG 检索文档的问答链路;多 Agent 的“家族分工”和调度器;调用监控、Trace、A/B...
一、行业痛点:认知偏差引发的测试决策危机 软件测试工程师常陷入确认偏差(过度关注预期结果而忽略异常场景)和群体思维&...
时间线:2024年2月 技术背景:各种\"越狱\"方法出现,Guardrails 技术成熟 我的状态:优...
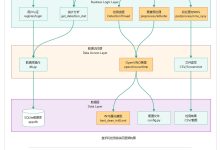
项目简介 基于改进YOLOv5n与OpenVINO加速的课堂手机实时检测系统,支持单张图片、视频文件及摄像头多模式检测,可自动记录...
一、前期准备数据处理:Pandas,高效读取文本 / Excel 文件,完成数据格式转换与拼接;中文分词...
